https://www.acmicpc.net/problem/2606
2606번: 바이러스
첫째 줄에는 컴퓨터의 수가 주어진다. 컴퓨터의 수는 100 이하인 양의 정수이고 각 컴퓨터에는 1번 부터 차례대로 번호가 매겨진다. 둘째 줄에는 네트워크 상에서 직접 연결되어 있는 컴퓨터 쌍
www.acmicpc.net
문제
신종 바이러스인 웜 바이러스는 네트워크를 통해 전파된다. 한 컴퓨터가 웜 바이러스에 걸리면 그 컴퓨터와 네트워크 상에서 연결되어 있는 모든 컴퓨터는 웜 바이러스에 걸리게 된다.
예를 들어 7대의 컴퓨터가 <그림 1>과 같이 네트워크 상에서 연결되어 있다고 하자. 1번 컴퓨터가 웜 바이러스에 걸리면 웜 바이러스는 2번과 5번 컴퓨터를 거쳐 3번과 6번 컴퓨터까지 전파되어 2, 3, 5, 6 네 대의 컴퓨터는 웜 바이러스에 걸리게 된다. 하지만 4번과 7번 컴퓨터는 1번 컴퓨터와 네트워크상에서 연결되어 있지 않기 때문에 영향을 받지 않는다.
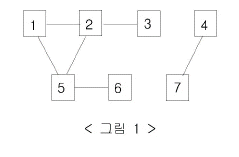
어느 날 1번 컴퓨터가 웜 바이러스에 걸렸다. 컴퓨터의 수와 네트워크 상에서 서로 연결되어 있는 정보가 주어질 때, 1번 컴퓨터를 통해 웜 바이러스에 걸리게 되는 컴퓨터의 수를 출력하는 프로그램을 작성하시오.
입력
첫째 줄에는 컴퓨터의 수가 주어진다. 컴퓨터의 수는 100 이하인 양의 정수이고 각 컴퓨터에는 1번 부터 차례대로 번호가 매겨진다. 둘째 줄에는 네트워크 상에서 직접 연결되어 있는 컴퓨터 쌍의 수가 주어진다. 이어서 그 수만큼 한 줄에 한 쌍씩 네트워크 상에서 직접 연결되어 있는 컴퓨터의 번호 쌍이 주어진다.
출력
1번 컴퓨터가 웜 바이러스에 걸렸을 때, 1번 컴퓨터를 통해 웜 바이러스에 걸리게 되는 컴퓨터의 수를 첫째 줄에 출력한다.
예제 입력
7
6
1 2
2 3
1 5
5 2
5 6
4 7예제 출력
4
dfs 와 bfs 알고리즘 모두로 접근 가능한 문제다.
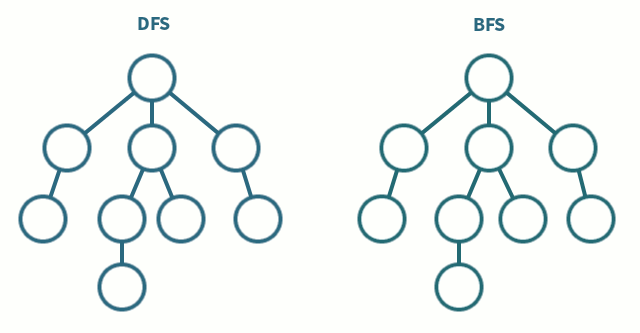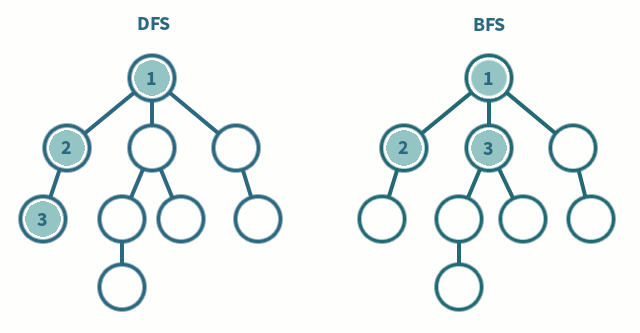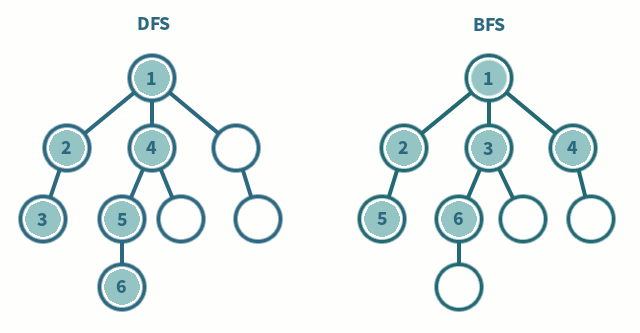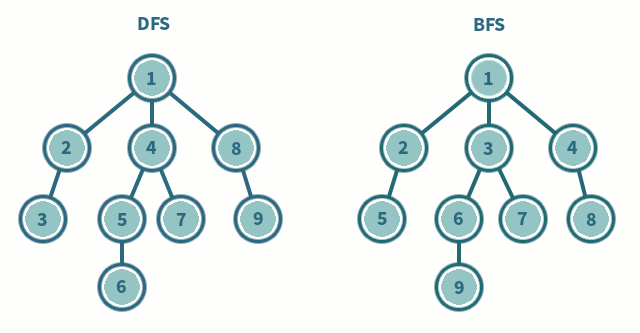
탐색해야 할 노드를 스택 또는 큐에 추가하고, 가장 최초로 방문해야 하는 노드를 first_node로 잡아 함수에 매개변수로 전달하도록 코드를 작성하는 편이 좋다. first_node와 연결된 모든 노드들을 차례로 탐색하는 방법이 bfs, first_node와 연결된 모든 노드들을 차례로 탐색하기 전에 first_node와 연결된 노드 중 가장 가까이 위치한(리스트 상에서 가장 앞에 위치한) 노드 하나만 파서 끝까지 탐색하는 방법이 dfs다. 우선 노드 한놈만 패고보는 dfs.

그리고 노드들을 방문할 때, 기존에 방문한 전적이 있는지를 확인해야 하는데, 이는 visited 리스트를 통해 가능하다. visited 리스트는 0부터 N번 노드까지의 인덱스가 차례대로 위치하며, 만약 노드 3번을 방문했다면 visited[3] == 1 이 참이다.
만약 노드 3번에 가장 가까이 연결된 4번 노드를 탐색할 경우, 4번 노드의 visited[4] == 0 일 경우에 한해, 4번 노드와 연결된 모든 노드의 값을 순차적으로 방문하고, visited[4] == 1로 변경한다.
전체 코드:
DFS Sol1
stack 활용
import sys
input = sys.stdin.readline
def dfs(first_node):
stack = [first_node]
while stack:
m = stack.pop()
if not visited[m]:
visited[m] = 1
stack.extend(graph[m]) # append 대신 extend를 써야 graph[m]의 모든 요소를 스택에 추가 가능
node = int(input())
edge = int(input())
graph = [[] for _ in range(node+1)]
visited = [0] * (node+1)
for _ in range(edge):
a, b = map(int, input().split())
graph[a].append(b)
graph[b].append(a)
dfs(1)
print(sum(visited) - 1)* 참고로 stack.extend(graph[m])에서 스택에 추가할 때 주의해야 함. dfs 깊이 탐색이 왼쪽에서 오른쪽으로 차차 진행되도록 만들고 싶으면, 그 순서를 정확히 지정해줘야 한다는 것. 스택은 LIFO 구조이므로, extend 시킬 때, 역순으로 집어넣어 주는 게 좋다. 아래와 같은 식으로
DFS Sol2
재귀 함수 활용
import sys
input = sys.stdin.readline
def dfs(first_node):
for i in graph[first_node]:
if visited[i] == 0:
visited[i] = 1
dfs(i)
node = int(input())
edge = int(input())
graph = [[] for i in range(node+1)]
visited = [0] * (node+1)
for i in range(edge):
a, b = map(int,input().split())
graph[a].append(b)
graph[b].append(a)
visited[1] = 1
dfs(1)
print(sum(visited)-1)
BFS Sol1
visited = [0] * (n+1) 과 같이 구현해 zero index 형태가 아니라 visited 리스트의 노드 인덱스 자체가 노드 넘버가 되도록 만들었다. 이 배열은 길이가 정해진 동적 배열.
import sys
input = sys.stdin.readline
from collections import deque
def bfs(first_node):
deq = deque([first_node])
while deq:
n = deq.popleft()
for i in graph[n]:
if visited[i] == 0:
deq.append(i)
visited[i] = 1
print(sum(visited)-1)
node = int(input())
edge = int(input()) # 또는 vertax
graph = [[] for _ in range(node+1)]
visited = [0]* (node+1)
for i in range(edge):
a, b = map(int, input().split())
graph[a].append(b) # grpah[a] += [b]
graph[b].append(a) # graph[b] += [a] 도 가능
visited[1] = 1
# print(graph)
bfs(1)
BFS Sol2
visited = [] 라고 구현해두고, 방문하게 되면 그 값을 visited.append('방문한 노드') 와 같이 구현.
import sys
input = sys.stdin.readline
from collections import deque
def bfs(first_node):
deq = deque([first_node])
while deq:
tmp = deq.popleft()
for i in graph[tmp]:
if i not in visited:
deq.append(i)
visited.append(i)
print(len(visited) -1)
node = int(input())
edge = int(input())
graph = [[] for _ in range(node+1)]
visited = []
for i in range(edge):
a, b = map(int,input().split())
graph[a].append(b)
graph[b].append(a)
visited.append(1)
bfs(1)

(이 문제에서는 DFS 알고리즘의 속도가 BFS 알고리즘보다 빨랐다.)
'Baekjoon Algorithm > python' 카테고리의 다른 글
| [Python]BAEKJOON 母音を数える (Counting Vowels) (0) | 2023.04.24 |
|---|---|
| [Python]BAEKJOON 11055번 (0) | 2023.03.15 |
| [Python]BAEKJOON 14002번 가장 긴 증가하는 부분 수열 4 (0) | 2023.03.14 |
| [Python]BAEKJOON 10816번 숫자카드 2 (2) | 2023.03.06 |
| [Python]BAEKJOON 10815번 숫자카드 (0) | 2023.03.06 |

댓글